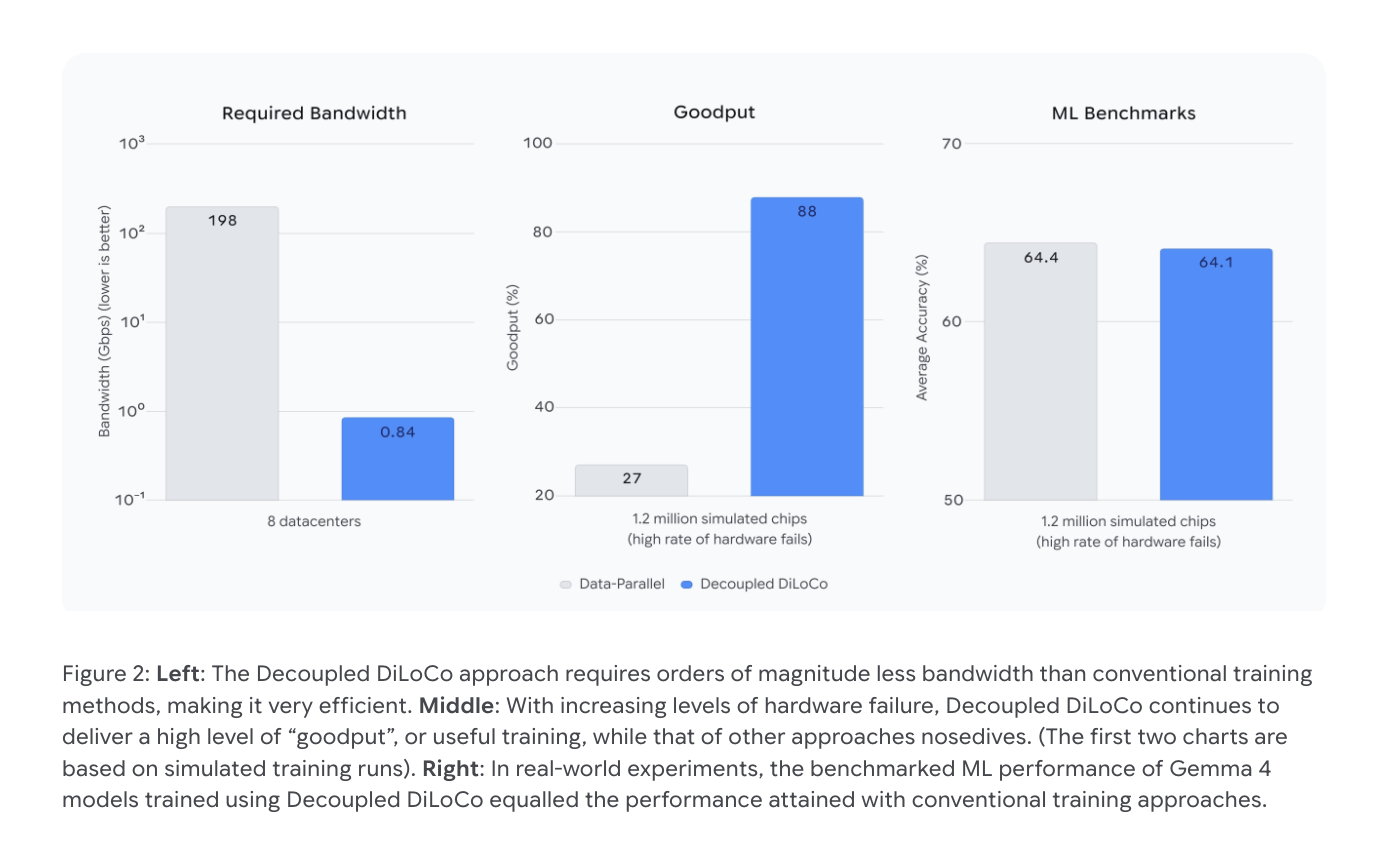
Google DeepMind представила архитектуру Decoupled DiLoCo для асинхронного обучения больших языковых моделей. По данным компании, новая система достигает 88% эффективности использования вычислительных ресурсов даже при высоких уровнях отказов оборудования.
Основная проблема при обучении фронтирных моделей ИИ заключается в необходимости постоянной синхронизации тысяч чипов. Каждое обновление градиентов требует координации по всей сети. При отказе одного чипа или его замедлении весь процесс обучения может остановиться. По информации Google DeepMind, эта уязвимость становится критической по мере увеличения размера моделей до сотен миллиардов параметров.
Декаплированная архитектура DiLoCo позволяет отдельным группам чипов обучаться независимо, а затем синхронизировать результаты. Компания заявляет, что такой подход снижает зависимость от синхронизации в реальном времени и повышает устойчивость к сбоям оборудования.
Аналитики отмечают, что асинхронное обучение может снизить операционные затраты на обслуживание инфраструктуры. Однако специалисты подчеркивают, что полная замена синхронных методов требует дополнительных исследований и валидации на различных масштабах.
Разработка архитектуры DiLoCo отражает растущий интерес индустрии к повышению надежности систем обучения ИИ при масштабировании. Google DeepMind продолжает работу над оптимизацией процессов подготовки моделей нового поколения.
Источник: Marktechpost
Реклама: 🔥 Хочешь получить Telegram Premium и стать гуру Polymarket? Кликай сюда!