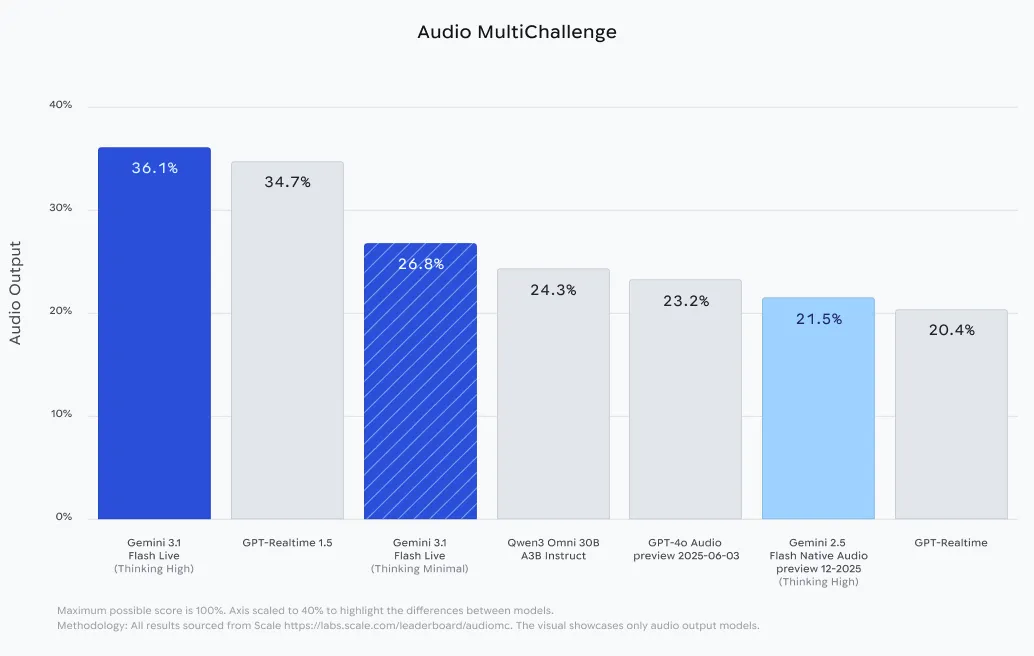
Google выпустила модель Gemini 3.1 Flash Live в режиме предварительного доступа для разработчиков через API Gemini Live в Google AI Studio. По данным компании, модель предназначена для низколатентных голосовых взаимодействий с обработкой аудио, видео и инструментов в реальном времени.
Модель обрабатывает мультимодальные потоки данных нативно, что позволяет строить приложения с поддержкой голосовых команд и видеоанализа. Google позиционирует Gemini 3.1 Flash Live как свою высокачественную модель для работы с аудио и речью на данный момент.
Модель поддерживает использование инструментов и интеграцию с внешними сервисами, что расширяет возможности AI-агентов. По информации компании, решение обеспечивает более естественное взаимодействие с пользователем за счет снижения задержек при обработке голоса.
ГGoogle подчеркивает, что модель находится на этапе предварительного доступа и предназначена для тестирования разработчиками. Компания не указала сроки полного выпуска или планы по расширению функциональности.
Источник: Marktechpost
Реклама: 🔥 Хочешь получить Telegram Premium и стать гуру Polymarket? Кликай сюда!