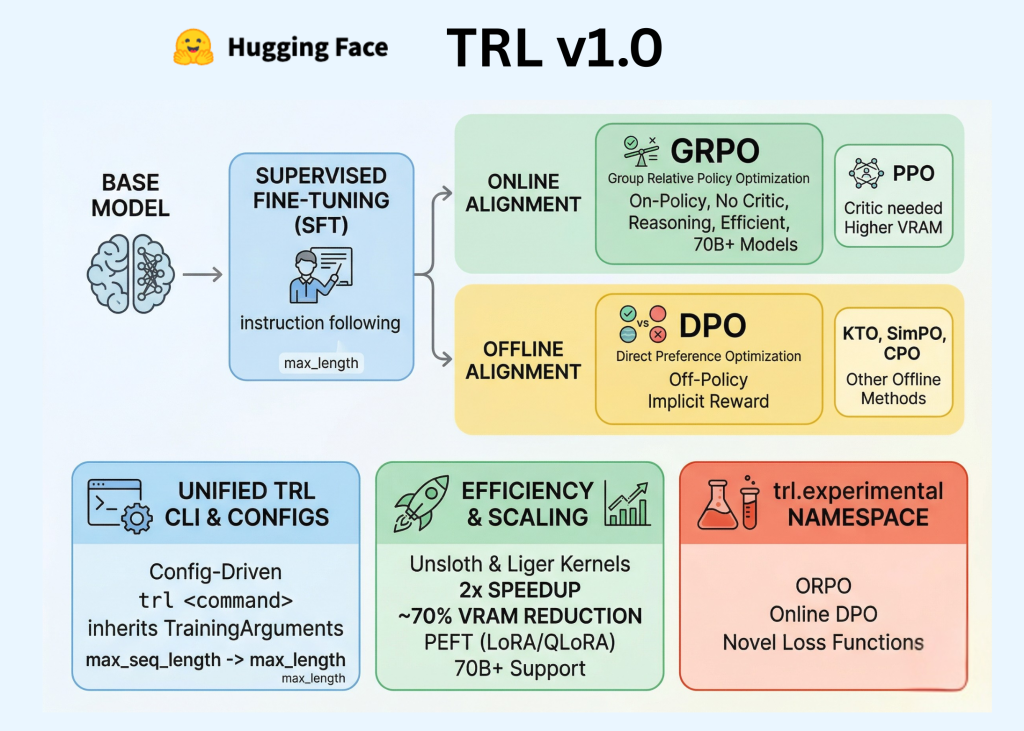
Hugging Face выпустила TRL (Transformer Reinforcement Learning) версии 1.0. По информации компании, библиотека перешла из статуса исследовательского проекта в производственный фреймворк.
TRL v1.0 объединяет основные этапы постобучения языковых моделей в единый API. Платформа поддерживает рабочие процессы Supervised Fine-Tuning (SFT), Reward Modeling, DPO и GRPO. По данным Hugging Face, унифицированный интерфейс упрощает реализацию стандартного конвейера выравнивания моделей.
Релиз позволяет разработчикам использовать одну библиотеку для всех этапов постобучения вместо интеграции нескольких инструментов. Компания заявляет о стабилизации API и готовности фреймворка к использованию в production-среде.
Переход на версию 1.0 означает, что основной функционал библиотеки достиг уровня зрелости, необходимого для промышленного применения. Hugging Face продолжает развивать экосистему инструментов для работы с большими языковыми моделями.
Источник: Marktechpost
Реклама: 🔥 Хочешь получить Telegram Premium и стать гуру Polymarket? Кликай сюда!