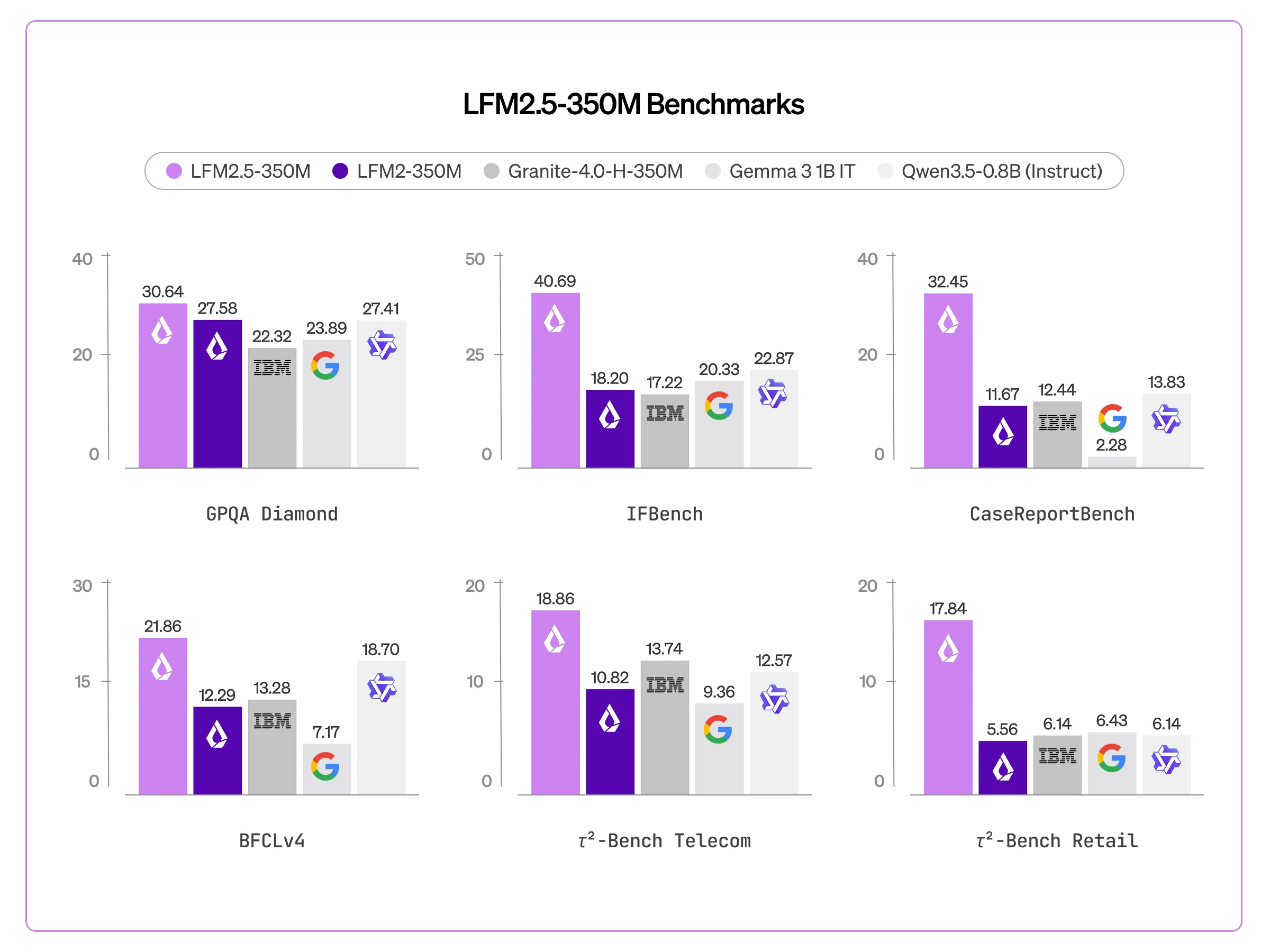
Liquid AI представила языковую модель LFM2.5-350M с 350 миллионами параметров. По данным компании, модель обучена на 28 триллионах токенов с применением масштабированного обучения с подкреплением.
Модель демонстрирует подход, альтернативный традиционному принципу масштабирования, согласно которому увеличение количества параметров напрямую повышает интеллектуальные возможности системы. Компания сосредоточилась на повышении плотности интеллекта через расширенное предварительное обучение, увеличив объем данных с 10 триллионов до 28 триллионов токенов.
Применение методов обучения с подкреплением позволило оптимизировать производительность модели при относительно компактном размере. По информации Liquid AI, такой подход обеспечивает баланс между вычислительной эффективностью и качеством выходных данных.
Компактные модели с оптимизированной архитектурой находят применение в развертывании на устройствах с ограниченными ресурсами. Аналитики отмечают растущий интерес индустрии к моделям, которые обеспечивают приемлемую производительность при сниженных требованиях к вычислительным ресурсам.
Источник: Marktechpost