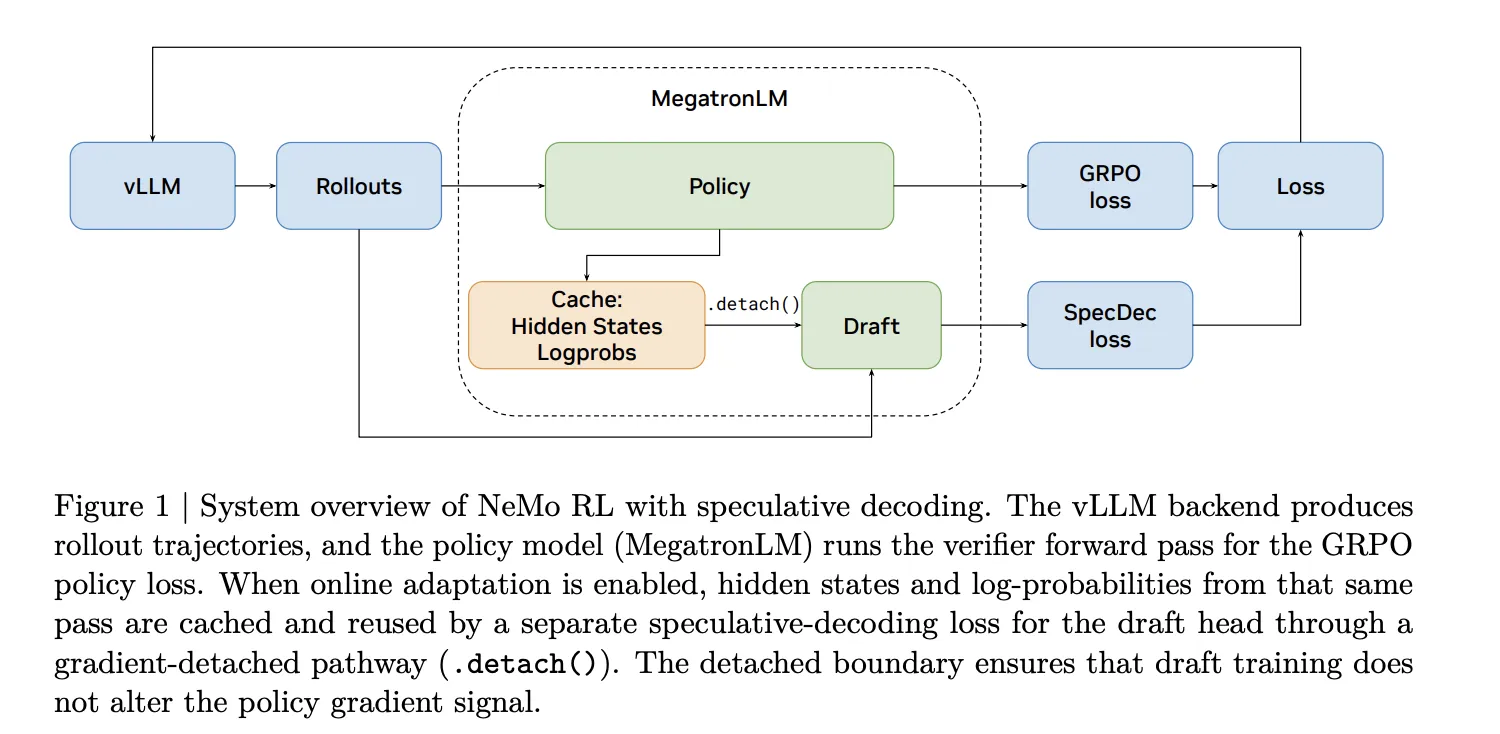
NVIDIA Research интегрировала технологию спекулятивного декодирования в фреймворк NeMo RL с бэкендом vLLM. По данным компании, решение обеспечивает ускорение генерации текста при обучении с подкреплением без потери качества.
На модели размером 8 млрд параметров достигнуто ускорение генерации роллаутов в 1,8 раза. Для модели масштаба 235 млрд параметров компания прогнозирует ускорение сквозной обработки в 2,5 раза.
Спекулятивное декодирование позволяет использовать меньшую модель для предварительного предсказания токенов, которые затем проверяются большей моделью. Это снижает количество обращений к основной модели и сокращает время вычислений.
Технология применима к процессам обучения с подкреплением, где требуется генерация большого объема текстовых данных для оценки политики модели. Интеграция в NeMo RL позволяет использовать ускорение на этапе сбора данных для обучения.
Решение работает с инфраструктурой vLLM, что обеспечивает совместимость с существующими развертываниями. NVIDIA указывает на сохранение качества генерируемого текста при использовании ускорения.
Источник: Marktechpost
Реклама: 🔥 Хочешь получить Telegram Premium и стать гуру Polymarket? Кликай сюда!